Basketball Player Tracker
Tracking players wherever they may be.

I wanted to create a system that could track players in a basketball clip and translate them to a coordinate grid.
Background
This kind of motion tracking already exists in the form of SportVU. But the aim of my project was to use the accessibility of YouTube clips to create my player tracking.
By satisfying this constraint the system would have the potential to be applied in college stadiums and foreign leagues where $100,000 installation of 6 cameras just isn’t feasible.
Player tracking has shown a lot of applications already in terms of strategic information, player health monitoring, and evaluating talent. Making it more accessible levels the playing field of analytics.
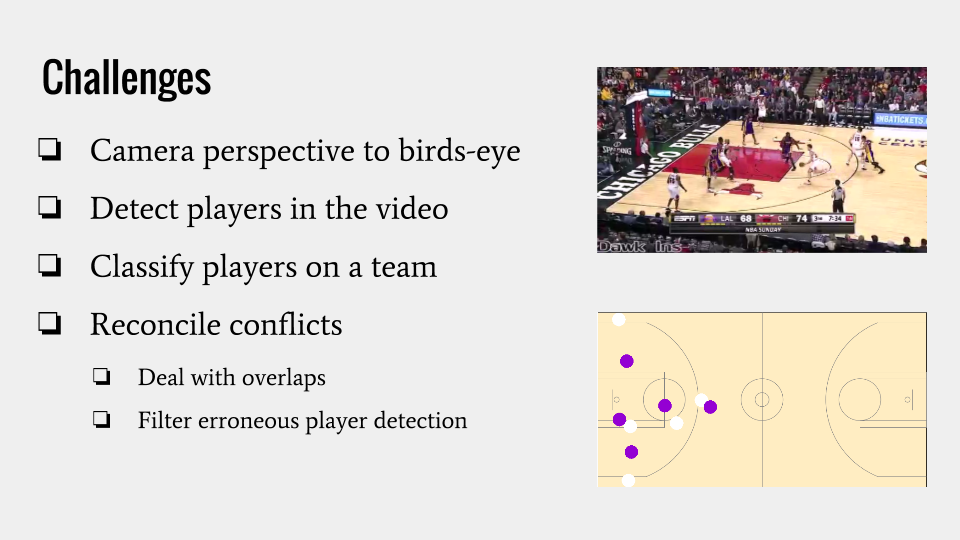
Challenges
Creating this system means I have to overcome a few challenges.
Projective Transform
After a series of filters, we find probabilistic Hough lines. Using the baseline, sideline, free throw line, and bottom of the free throw lane, we can create a map. Since the dimensions of a real court are known, we can place objects on the drawn court.
![]()
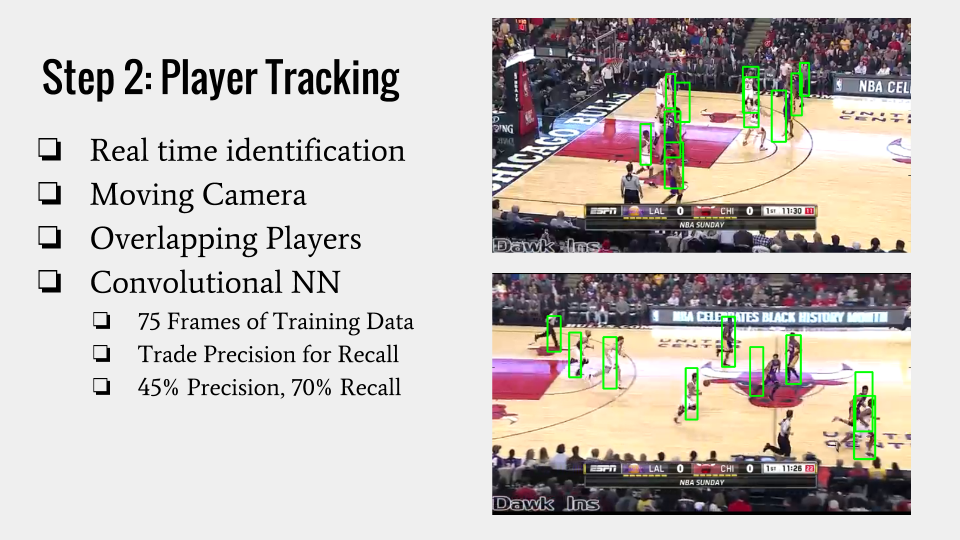
Player Identification
The next challenge we need to address is identifying players in each frame. Issues such as overlapping players and distorted lighting make this a significant challenge. I applied a convolutional neural network based on OverFeat. The model is implemented using TensorBox and creates bounding boxes on identified players.
Here’s a Youtube video one of the early iterations applied to a Youtube highlight reel.
The detection model has a parameter for threshold which allows less confident boxes to be included. By reducing this threshold to 30% confidence, I increased my recall by 40% with a loss in precision. The false positives will be filtered out in the next stage.
Filtering and Error Detection
I choose two colored filters, in this case purple and white, based on the teams that are playing. By applying a white and purple filter to each bounding box I can create a feature, color occurrence frequency, that allows me to classify players by team.
Furthermore, I can filter out erroneous bounding boxes by using this and detecting neither team color in the photo.

Results
When all these steps are applied to each frame of the video, the video can be reconstructed and looks something like this.
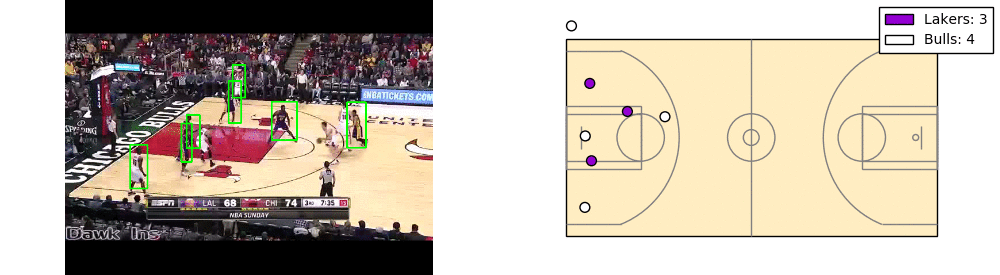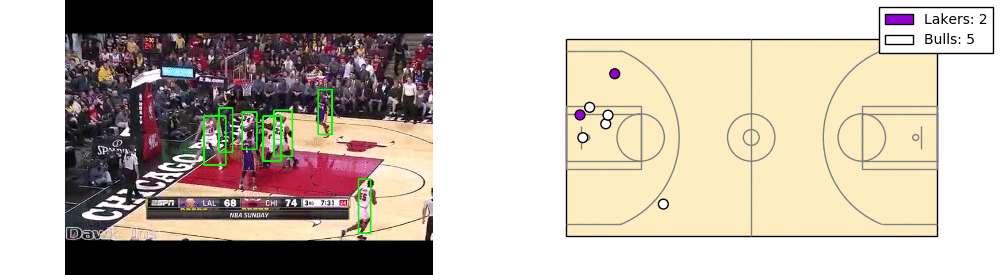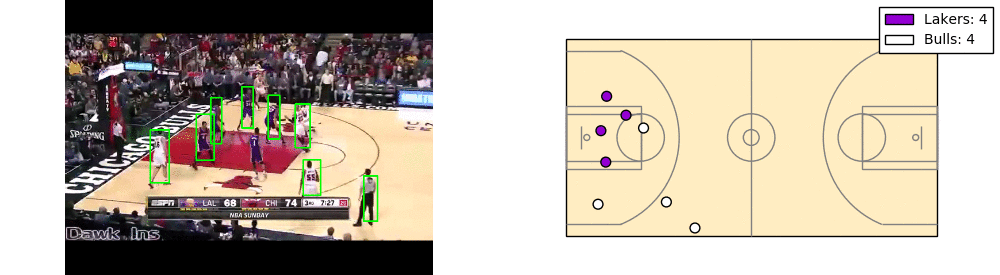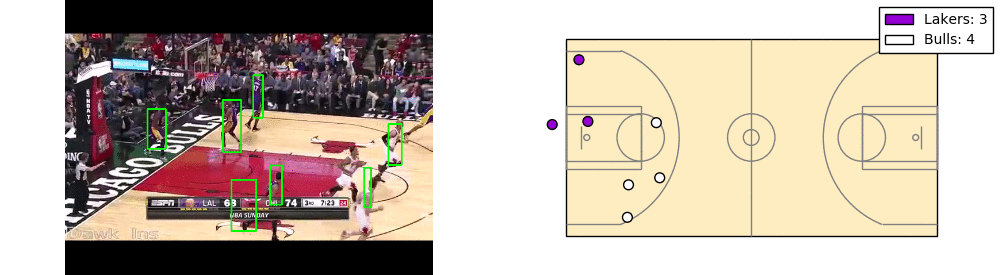
There’s a lot of room for improvement here. As you can see players cut in and cut out. Also the coordinates have significant noise.
The takeaway is that each player can be mapped to a location on the court, based on their position on the screen and the landmarks on the court.
Future work
The model is trained on only 75 frames of training data. I’d definitely look here to begin with improvements.
To make the translation more versatile, I need to improve the handling of court detection. This is particularly an issue when crossing half court. Trying to detect objects on the court rather than lines might be more resistant to obstruction and ultimately prove more flexible.
Next leveraging the temporal nature of film, I can reduce jittering by interpolating points between frames. A Kalman filter might be applicable here.
Finally I want to create a time series where I can link rectangles to each other. My idea for this is to use either the Kalman filter or a HMM to create the continuous sequence of coordinates based on a probability function including distance and color.
So there’s plenty of future work to do, and if you’d like to take a look at the code and try some of it for yourself check it out on my github.